PIILOT - AI 기반 개인정보 보호 플랫폼
기업 인프라에 산재된 개인정보를 AI 모델로 자동 탐지하고 비식별화하여 보안 및 법적 리스크를 최소화하는 통합 관제 플랫폼.
Background
생성형 AI 기술의 확산과 함께 기업의 개인정보 유출 사고가 급격히 증가하고 있다. 국내 기업 개인정보 유출 건수는 2022년 167건에서 2025년 451건 이상으로 3년간 170% 증가하였다. 대형 통신사 2,324만 명 개인정보 유출로 과징금 1,348억 원이 부과되는 등 사회적 피해 규모가 역대 최대 수준을 기록하고 있다.
법적 환경도 빠르게 변화하고 있다. 2025년 개정된 개인정보보호법에 따라 위반 시 과징금 상한이 매출의 3% → 10%로 대폭 상향되어 기업의 법적 리스크가 크게 커졌다. 그러나 기업 현장에서는 아래 세 가지 구조적 문제가 해결되지 않은 채 방치되어 있었다.
- 개인정보 위치 파악의 한계 - 시스템 전반에 개인정보가 분산되어 전체 현황 및 암호화 여부 파악 불가
- 비효율적인 수작업 처리 - 개인정보 탐지·마스킹을 수동으로 수행하며, 보안 사고의 68%가 인적 오류에서 발생
- 법적 리스크 관리 취약 - 개인정보보호법·내규 등 복잡한 규제 속에서 법령 준수 여부 확인이 어려움
PIILOT은 이 세 가지 문제를 AI 자동화로 해결하는 것을 목표로 설계되었다. 수동 점검 중심의 기존 방식과 달리, AI 기반 자동 탐지로 관리 범위를 확대하고 사후 대응이 아닌 사전 탐지 기반 예방으로 패러다임을 전환하였다.
Overview
기업 환경의 DB·파일 서버에 분산된 개인식별정보(PII)를 AI 모델이 자동으로 탐지·비식별화하는 통합 관제 플랫폼이다. 개인정보 유출을 사전에 방지하고 탐지하는 것을 목적으로, 문서·이미지 하이브리드 비식별화 파이프라인과 2단계 XGBoost 분류 아키텍처를 핵심 AI 엔진으로 구성하였다.
총 54일간(2025.12.29 - 2026.02.20) 진행된 KT AIVLE School 8기 Bigproject로, AI 6명, BE 4명, FE 2명, Infra 2명으로 구성된 14인 팀이 개발하였다. 최종 발표에서 AI 트랙 대상(1위)을 수상하였다.
Key Features
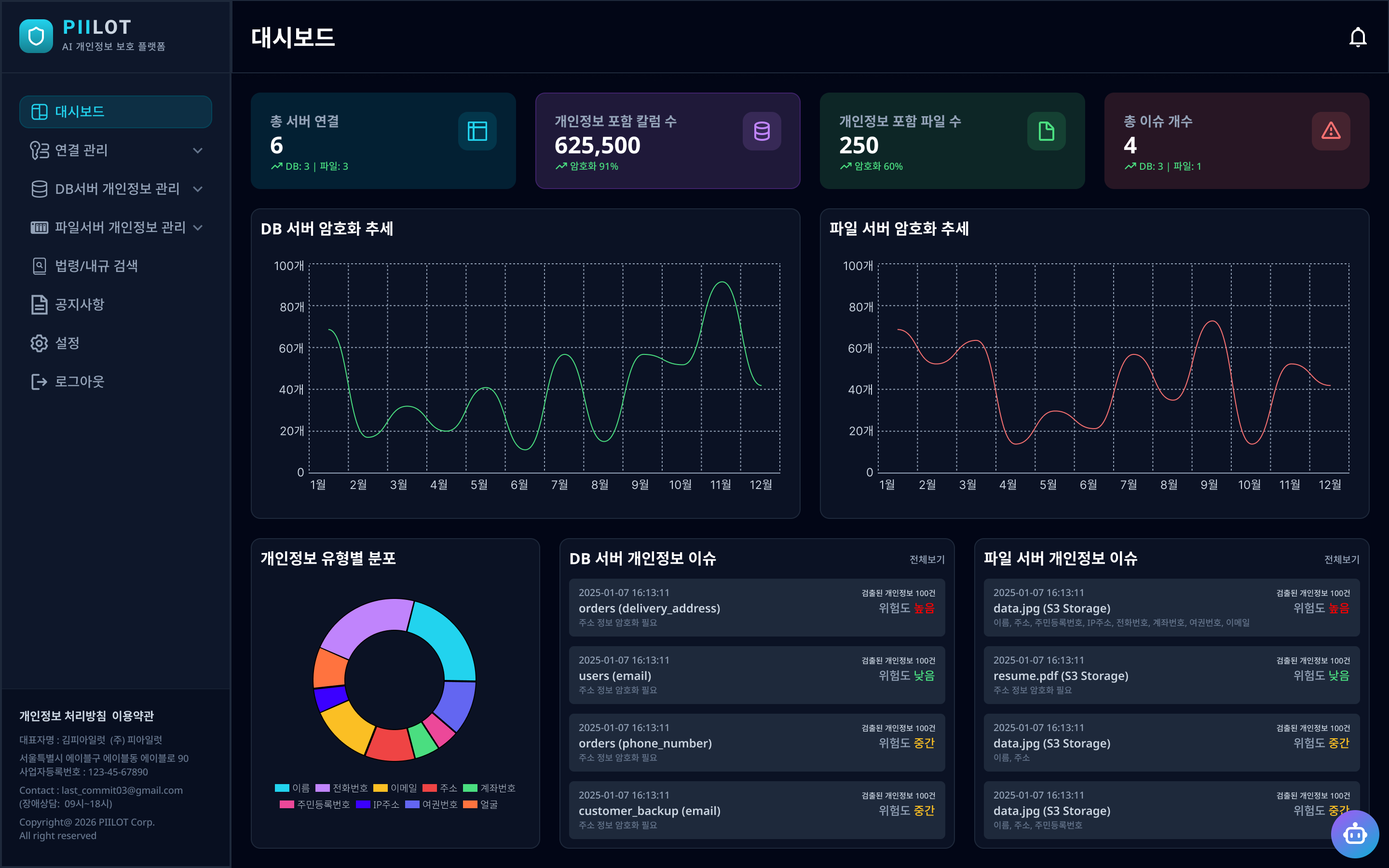
대시보드에서 연결된 서버 수, 개인정보 포함 컬럼/파일 수, 총 이슈 개수를 한눈에 파악할 수 있으며, DB·파일 서버별 암호화 추세와 개인정보 유형 분포를 실시간 차트로 제공한다.
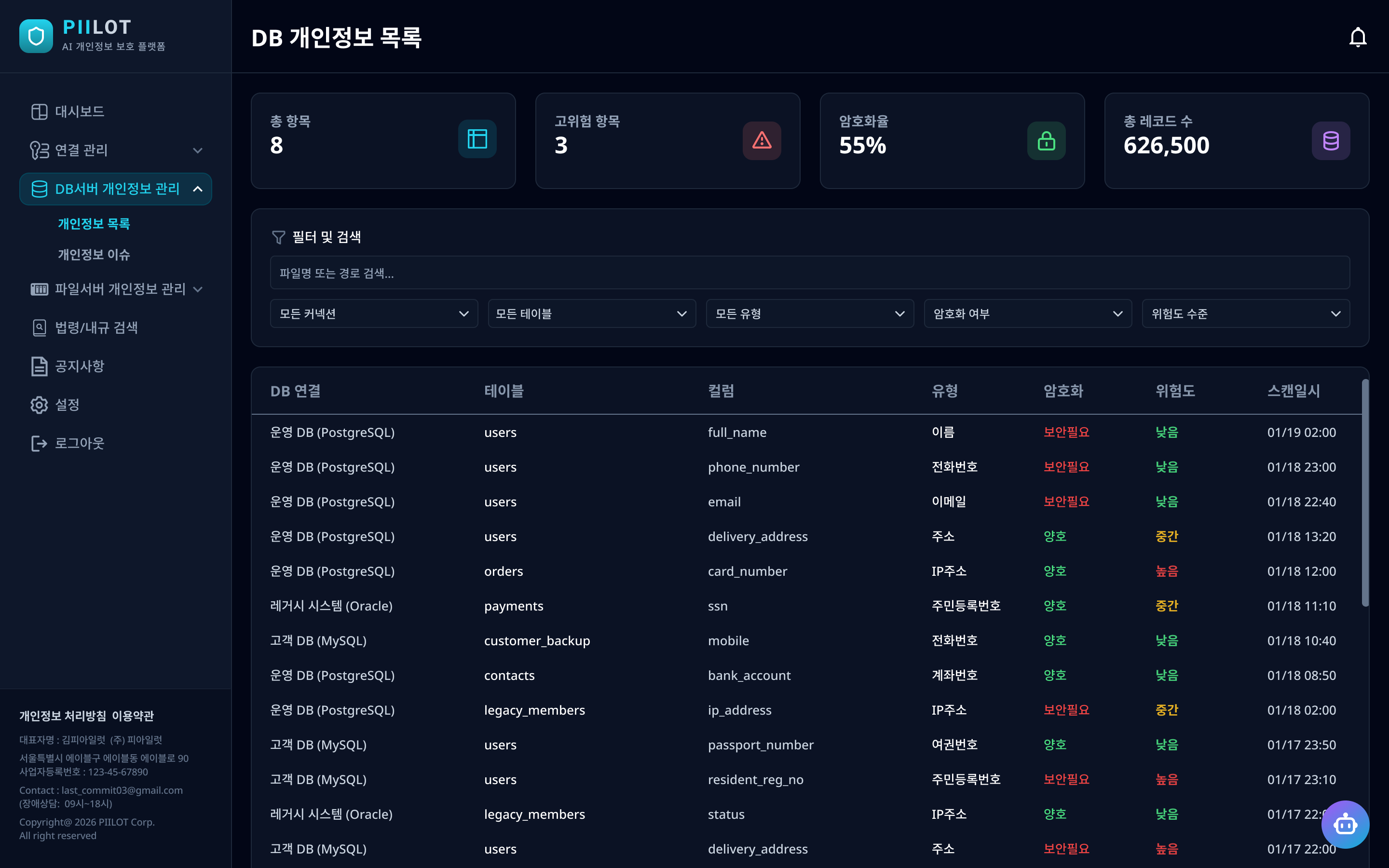
DB 서버와 파일 서버를 연결하여 개인정보가 포함된 컬럼·파일을 탐지하고, 암호화 여부·위험도·스캔 이력을 관리한다. DB 스캔은 변경된 테이블만 재스캔하는 Change Signature 방식으로 재스캔 시 약 93% 시간 단축을 달성하였다.
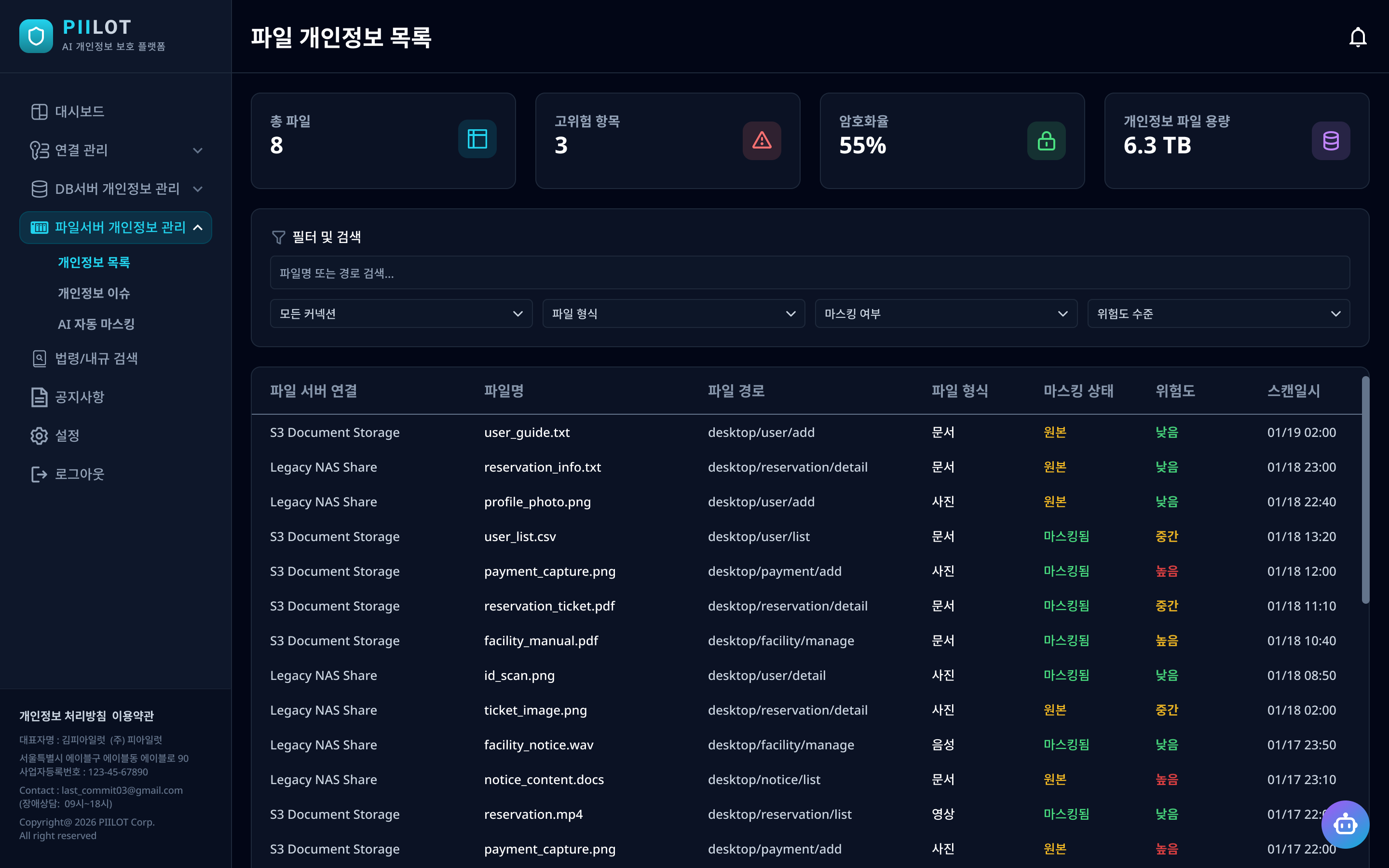
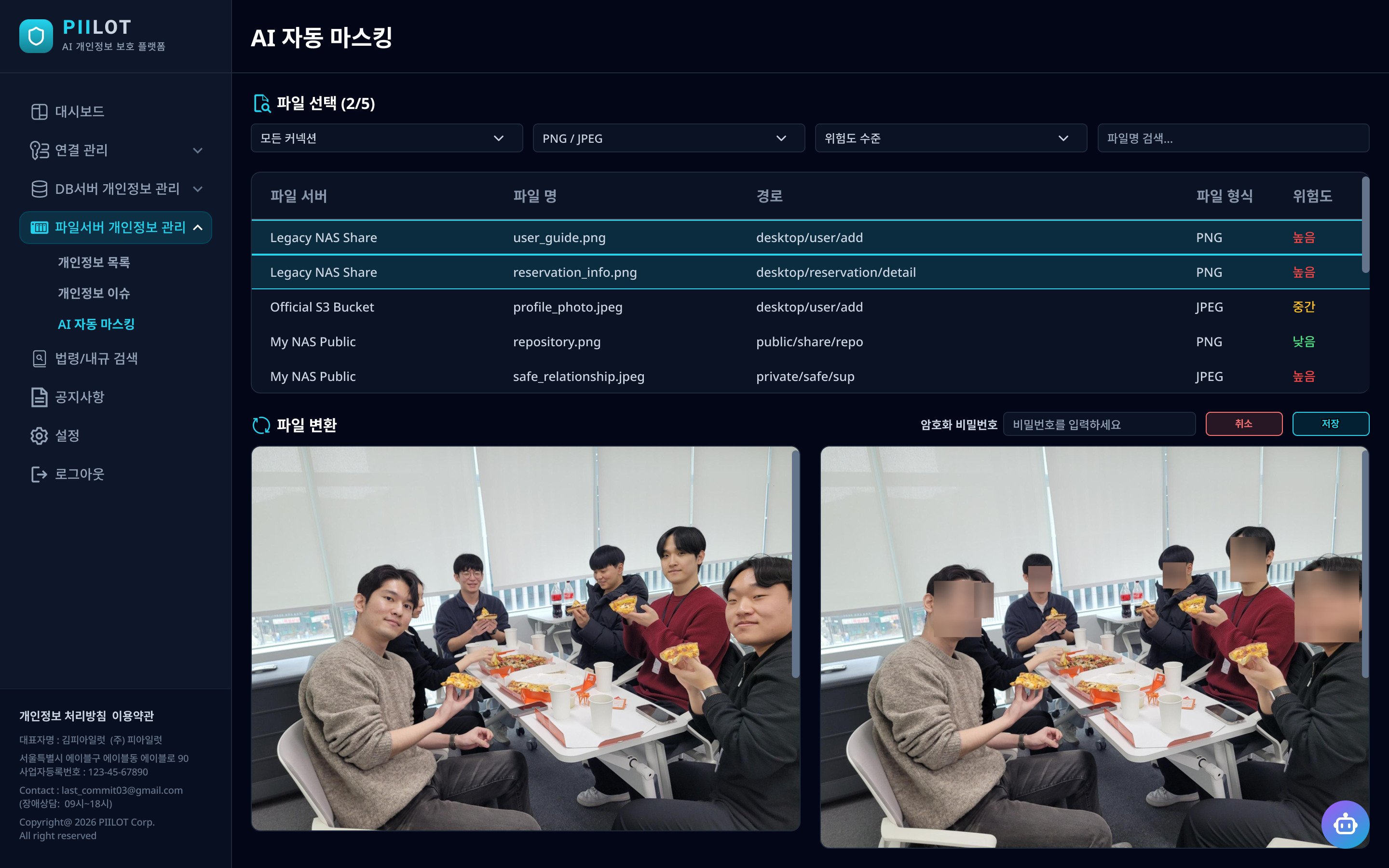
AI 자동 마스킹 (Auto Masking)
이미지·문서·오디오·비디오 파일 내의 개인정보를 AI 모델이 자동으로 감지하여 마스킹 처리한다. 얼굴·개인식별 정보가 담긴 이미지를 선택하면 변환 결과를 실시간으로 미리볼 수 있으며, 비식별화 전·후를 나란히 비교할 수 있다. 마스킹된 파일은 Redis에 30분간 캐싱하여 저장 시 AI 서버 재호출 없이 즉시 처리되며, 원본 파일은 ZIP AES 암호화 후 별도 저장된다.
Approach
AI - PII 합성 데이터셋 설계 및 동적 생성
- AI 학습용 PII 합성 데이터셋 설계 및 동적 생성 (8,500개, BIO 태깅 포맷)
- 이름·주민번호·주소·계좌번호·IP주소·전화번호·이메일·여권번호 8종 클래스 정의
- 특정 PII 쏠림 현상 방지 - Exponential Weighting 기반 동적 가중치 알고리즘으로 8개 클래스 균형 확보 (클래스별 약 450개)
- Zero-Shot 평가 결과 F1-Score 0.0021 확인 후 Fine-Tuning 방향으로 전환
AI - 문서/이미지 하이브리드 비식별화 파이프라인
- KoELECTRA-base-v3 NER Fine-Tuning: 이름·주소 등 비정형 패턴을 문맥 기반으로 탐지
- 정규식 패턴 매칭(Regex): 전화번호·이메일·주민번호 등 형식이 명확한 데이터와 상호 보완
- YOLOv12n-face + EasyOCR: 이미지 내 얼굴 탐지 및 텍스트 추출, 좌표 기반 블러 처리
- faster-whisper-large-v3: STT 변환 후 NER으로 음성 내 개인정보 탐지 및 1000Hz Sine Wave 마스킹
- Kalman Filter: 영상 프레임 간 객체 추적으로 마스킹 연속성 확보
- NER Fine-Tuning 결과: Recall 96.3%, F2 Score 86.1%
AI - DB 레코드 암호화 여부 판별 모델 (2단계 XGBoost)
- 1차 분류(이진): 계좌번호 여부를 우선 판별하여 혼동 클래스 분리
- 2차 분류(다중): 7종 PII 또는 NONE으로 세분화하여 최종 암호화 여부 판별
- 은행코드 50+ 패턴, 유효 계좌 길이 등 금융·보안 도메인 지식 반영 (도메인 특징 60+ 추가 학습)
- 기본 XGBoost 대비 정확도 80% 향상, 최종 정확도 94.4% 달성 (84 / 89)
AI - DB 컬럼 개인정보 탐지 (RAG + LLM)
- RAG + KT 믿:음 2.0(LLM)으로 DB 컬럼명을 8종 개인정보로 분류
- 기업별 용어사전 업로드로 커스텀 대응 가능
- Hybrid Search(BM25 + Vector) + FlashRank 재순위화로 법령 검색 정확도 최적화
BE - 백엔드 API 구현
- 파일 개인정보 목록 API 구현
- 개인 알림 시스템 API 구현
- QueryDSL 도입으로 복잡한 조건 필터링·통계 효율화
- COUNT 쿼리 병목을 Slice 기반 페이징으로 전환하여 DB I/O 성능 개선
- 파일 마스킹 Redis 캐싱: 마스킹 결과(~133MB)를 TTL 30분으로 서버 캐싱하여 저장 API 응답 최대 99.96% 개선
BE: 파일 개인정보 목록 API 구현, 개인 알림 시스템 API 구현
Tech Stack
Results
- DB 레코드 암호화 여부 판별 모델 최종 정확도 94.4% 달성 - 기본 XGBoost 대비 80% 향상
- NER Fine-Tuning 결과 Recall 96.3%, F2 Score 86.1% - 미탐(FN)이 법적 리스크로 직결되므로 Recall 극대화 목표
- DB 재스캔 시 약 93% 시간 단축 (Change Signature 기반 증분 스캔)
- 파일 마스킹 Redis 캐싱 도입으로 저장 API 응답 최대 99.96% 개선 (영상 214,892ms → 89ms)
- 기대 효과: 개인정보 유출 사고 최대 90% 감소, 컴플라이언스 위반 리스크 최대 70% 감소
- 기대 효과: AI 자동화로 작업시간 최대 85% 단축, 운영 비용 연간 5억 원 절감
- KT AIVLE School 8기 AI 트랙 빅프로젝트 대상(1위) 수상